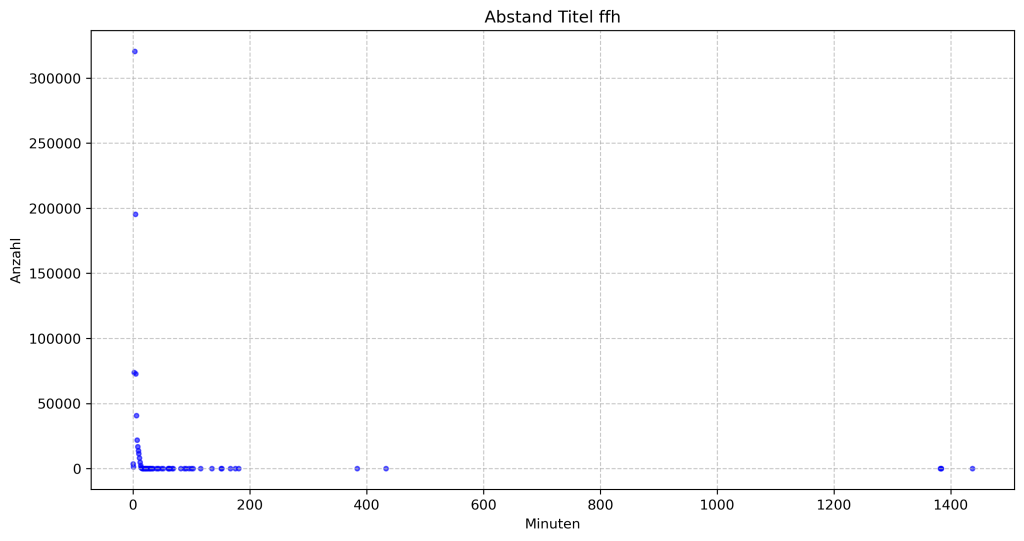
Die Frage, ab wann „Last Christmas“ von „WHAM!“ das erste Mal im Jahr gespielt wird, lässt sich gar nicht so pauschal beantworten, wie ich es bei der Q&A vielleicht versucht hatte, darzustellen. Der Hintergrund davon ist, dass die Sender gerne aus Gag oder aus einem anderen Zusammenhang den Song auch schon im März oder Juli bereits „zum ersten Mal in diesem Jahr“ spielen:
| Sender | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | 2023 | 2024 |
| 1Live | 23.12.19 | 07.12.20 | 22.12.22 | 24.09.23 | 07.08.24 | ||||
| MDRSputnikLive | 24.12.19 | 01.04.21 | 24.12.24 | ||||||
| absolutehot | 23.11.22 | ||||||||
| antennemv | 23.12.19 | 29.11.20 | |||||||
| antenneniedersachsen | 25.10.20 | 06.04.21 | 27.11.22 | 02.12.23 | 24.10.24 | ||||
| bayern3 | 02.12.19 | 06.01.20 | 22.03.21 | 24.06.22 | 24.08.23 | 03.06.24 | |||
| bigfm | 17.12.16 | 09.12.17 | 08.12.18 | 07.12.19 | 25.03.21 | 14.03.23 | 06.12.24 | ||
| bigfmsaar | 09.12.17 | 08.12.18 | 07.12.19 | 25.03.21 | 06.12.24 | ||||
| bremennext | 14.03.23 | ||||||||
| bremenvier | 08.11.19 | 19.01.20 | 28.10.21 | 25.11.22 | 14.03.23 | 25.11.24 | |||
| dasding | 05.04.19 | 06.03.20 | 01.04.21 | 11.11.22 | 31.03.23 | 26.04.24 | |||
| egofm | 15.12.19 | 14.12.20 | 24.12.21 | 23.12.22 | 12.12.23 | 03.12.24 | |||
| ffh | 26.11.18 | 22.02.19 | 15.09.20 | 09.04.21 | 24.11.22 | 01.12.23 | 01.05.24 | ||
| ffn | 01.12.18 | 23.04.19 | 28.11.20 | 27.11.21 | 27.11.22 | 10.04.23 | 01.04.24 | ||
| hitradiortl | 24.12.19 | 26.11.22 | 27.11.23 | 24.10.24 | |||||
| hr3 | 19.12.19 | 07.08.20 | 24.11.22 | 10.11.23 | 03.06.24 | ||||
| jamfm | 23.09.21 | 26.11.22 | 16.12.23 | 14.12.24 | |||||
| kissfm | 02.12.19 | 24.12.22 | 27.08.24 | ||||||
| mdrjump | 29.11.19 | 27.11.20 | 26.11.21 | 21.11.22 | 27.11.23 | 29.11.24 | |||
| ndr2 | 03.12.17 | 05.09.18 | 29.11.19 | 24.11.20 | 24.11.21 | 25.11.22 | 03.01.23 | 24.03.24 | |
| njoy | 21.04.19 | 11.04.20 | 04.04.21 | 16.04.22 | 08.04.23 | 30.03.24 | |||
| planet | 17.12.18 | 15.12.19 | 11.12.20 | 03.12.21 | 29.11.22 | 07.09.23 | 05.11.24 | ||
| puls | 18.12.19 | 04.12.20 | 21.06.21 | 09.11.22 | 07.11.23 | 24.12.24 | |||
| radio91.2 | 15.09.20 | 24.08.22 | 07.11.23 | 15.11.24 | |||||
| rpr1 | 21.04.19 | 01.12.20 | 22.10.21 | 13.01.22 | 28.11.23 | 01.12.24 | |||
| rsh | 22.12.19 | 13.04.20 | 17.04.22 | 10.04.23 | 30.03.24 | ||||
| rtl | 30.11.20 | 25.11.22 | 27.11.23 | 25.11.24 | |||||
| spreeradio | 29.11.20 | 28.11.22 | 27.11.23 | 25.11.24 | |||||
| sr1 | 26.11.20 | 03.05.22 | 10.11.23 | 01.05.24 | |||||
| swr3 | 24.07.17 | 24.01.18 | 30.05.19 | 24.11.22 | 20.02.23 | 16.01.24 | |||
| top40 | 29.04.21 | 24.11.22 | 11.11.24 | ||||||
| unserding | 15.02.21 | 11.11.22 | |||||||
| wdr2 | 20.12.19 | 21.03.20 | 19.11.22 | 25.06.23 | 16.01.24 | ||||
| youfm | 23.12.19 | 03.04.20 | 16.07.21 | 25.11.22 | 20.02.23 | 03.12.24 |
Und hier zum Vergleich, wenn man ab dem 01.10. des jeweiligen Jahres erst zählt:
| sender | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | 2023 | 2024 |
| 1Live | 23.12.19 | 07.12.20 | 22.12.22 | 17.11.23 | 11.10.24 | ||||
| MDRSputnikLive | 24.12.19 | 24.12.24 | |||||||
| absolutehot | 23.11.22 | ||||||||
| antennemv | 23.12.19 | 29.11.20 | |||||||
| antenneniedersachsen | 25.10.20 | 27.11.22 | 02.12.23 | 24.10.24 | |||||
| bayern3 | 02.12.19 | 13.11.20 | 13.10.21 | 24.10.22 | 24.11.23 | 31.10.24 | |||
| bigfm | 17.12.16 | 09.12.17 | 08.12.18 | 07.12.19 | 06.10.21 | 06.12.24 | |||
| bigfmsaar | 09.12.17 | 08.12.18 | 07.12.19 | 06.10.21 | 06.12.24 | ||||
| bremennext | 09.11.23 | ||||||||
| bremenvier | 08.11.19 | 18.11.20 | 28.10.21 | 25.11.22 | 09.11.23 | 25.11.24 | |||
| dasding | 12.11.19 | 11.11.22 | 24.11.23 | 29.11.24 | |||||
| egofm | 15.12.19 | 14.12.20 | 24.12.21 | 23.12.22 | 12.12.23 | 03.12.24 | |||
| ffh | 26.11.18 | 25.11.19 | 27.11.20 | 26.11.21 | 24.11.22 | 01.12.23 | 01.12.24 | ||
| ffn | 01.12.18 | 24.10.19 | 28.11.20 | 27.11.21 | 27.11.22 | 06.12.23 | 03.12.24 | ||
| hitradiortl | 24.12.19 | 26.11.22 | 27.11.23 | 24.10.24 | |||||
| hr3 | 19.12.19 | 27.11.20 | 24.11.22 | 10.11.23 | 05.11.24 | ||||
| jamfm | 26.11.22 | 16.12.23 | 14.12.24 | ||||||
| kissfm | 02.12.19 | 24.12.22 | 24.12.24 | ||||||
| mdrjump | 29.11.19 | 27.11.20 | 26.11.21 | 21.11.22 | 27.11.23 | 29.11.24 | |||
| ndr2 | 03.12.17 | 16.11.18 | 29.11.19 | 24.11.20 | 24.11.21 | 25.11.22 | 03.12.23 | 26.11.24 | |
| njoy | 17.11.19 | 17.10.20 | 28.11.21 | 24.11.22 | 17.11.23 | 01.12.24 | |||
| planet | 17.12.18 | 15.12.19 | 11.12.20 | 03.12.21 | 29.11.22 | 01.12.23 | 05.11.24 | ||
| puls | 18.12.19 | 04.12.20 | 09.11.22 | 07.11.23 | 24.12.24 | ||||
| radio91.2 | 24.11.20 | 28.11.22 | 07.11.23 | 15.11.24 | |||||
| rpr1 | 27.11.19 | 01.12.20 | 22.10.21 | 09.11.22 | 28.11.23 | 01.12.24 | |||
| rsh | 22.12.19 | 26.11.20 | 24.11.22 | 10.11.23 | 29.11.24 | ||||
| rtl | 30.11.20 | 25.11.22 | 27.11.23 | 25.11.24 | |||||
| spreeradio | 29.11.20 | 28.11.22 | 27.11.23 | 25.11.24 | |||||
| sr1 | 26.11.20 | 02.12.22 | 10.11.23 | 29.11.24 | |||||
| swr3 | 01.12.17 | 14.11.18 | 02.12.19 | 24.11.22 | 02.11.23 | 02.11.24 | |||
| top40 | 23.12.21 | 24.11.22 | 11.11.24 | ||||||
| unserding | 11.11.22 | ||||||||
| wdr2 | 20.12.19 | 24.11.20 | 19.11.22 | 18.11.23 | 05.10.24 | ||||
| youfm | 23.12.19 | 06.11.20 | 25.11.22 | 06.12.23 | 03.12.24 | ||||